IBM construyó una supercomputadora gigante de IA en la nube para entrenar sus modelos masivos de IA


Se ha prestado mucha atención a la inteligencia artificial desde que OpenAI presentó su modelo de lenguaje de IA llamado ChatGPT. El interés público aumentó después de obtener una prueba práctica y gratuita de la IA. La respuesta fue tan buena que Microsoft y Google se vieron obligados a integrar rápidamente la IA en sus infraestructuras de motores de búsqueda. El lanzamiento de ChatGPT probablemente será un punto de inflexión en la evolución de la IA.
IBM Research tiene una posición de liderazgo de larga data en IA
OpenAI y Google no son las únicas empresas que realizan una extensa investigación sobre IA. IBM tiene uno de los programas de IA de investigación más grandes y mejor financiados del mundo. Décadas de trabajo con inteligencia artificial han mantenido a la empresa a la vanguardia de la investigación avanzada en IA.
Recientemente, IBM se ha centrado en la creación de modelos de IA que agilicen las operaciones de las unidades de negocio internas de IBM. Este trabajo no solo hace que IBM opere de manera más eficiente, sino que también permite a sus investigadores obtener una valiosa experiencia para perfeccionar aún más la tecnología. IBM también ha estado realizando investigaciones innovadoras de IA en áreas que afectan la vida, como la química, la biología, la medicina y la atención médica.
Una cantidad significativa de la investigación reciente de IBM se ha dedicado a los modelos básicos y la IA generativa. Estos modelos están entrenados en grandes cantidades de datos sin etiquetar y se pueden usar para múltiples tareas con solo pequeñas modificaciones. Los modelos básicos son enormes, generalmente con miles de millones de parámetros. Los modelos de esta escala son tan grandes que solo pueden entrenarse con supercomputadoras.
Desafortunadamente, las supercomputadoras clásicas no fueron diseñadas para la complejidad computacional necesaria para el entrenamiento óptimo de modelos de IA. IBM se dio cuenta de que construir una supercomputadora de IA con una arquitectura diseñada para construir y entrenar modelos masivos de IA sería beneficioso para sus esfuerzos de investigación y, eventualmente, para sus clientes.
La decisión de construir una supercomputadora de IA fue fácil, sin embargo, después de una buena cantidad de debate interno, IBM decidió que debería construirse en la nube.
Según la Dra. Talia Gershon, Directora de Investigación de Infraestructura en la Nube, IBM se ha dedicado a desarrollar una infraestructura en la nube de alto rendimiento y centrada en la IA durante muchos años.
“En IBM Research, nos estamos inclinando mucho hacia los modelos básicos”, dijo el Dr. Gershon. “Nuestra investigación en esta área ha sido notable e innovadora. Debido al rendimiento que ofrecen estos modelos y la capacidad de adaptarse rápidamente con un tiempo mínimo para lograr valor, IBM ve los modelos básicos como una oportunidad enorme y disruptiva que estamos decididos a aprovechar”.
IBM ha desarrollado una serie de modelos de IA generativa para varios dominios relacionados con la vida y relacionados con el negocio, como los antimicrobianos, la química, los materiales y el código. Puede leer más información sobre esta clase particular de modelos en mi artículo anterior de Forbes.com aquí.
Construyendo el modelo
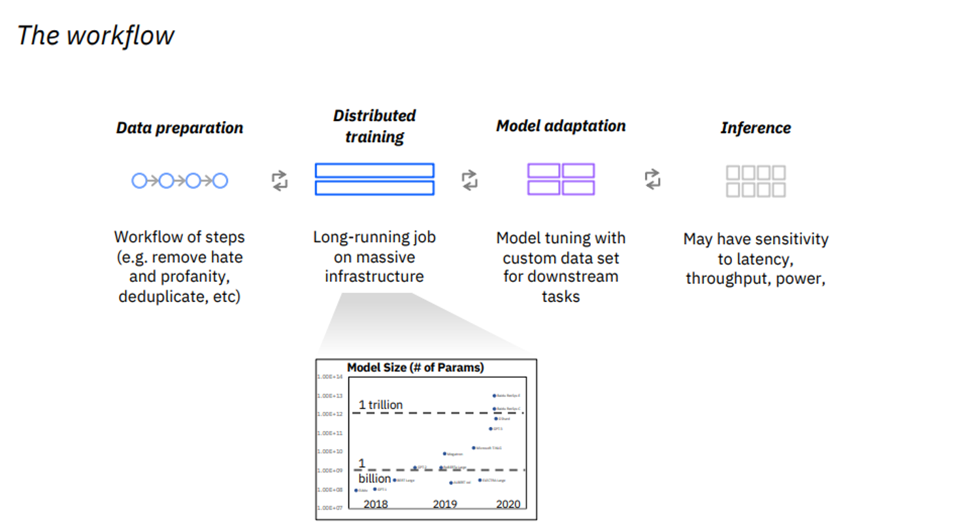
El Dr. Gershon explicó por qué desarrollar modelos básicos masivos es una tarea desafiante y que requiere mucho tiempo, ya que a menudo requiere docenas o incluso cientos de GPU para funcionar durante semanas o meses durante la fase de capacitación.
Explicó además que para garantizar un flujo de trabajo eficiente en la creación de modelos, se debe prestar especial atención a cada paso del proceso, desde la recopilación y preparación inicial de datos hasta la validación y, finalmente, la puesta en funcionamiento. Los datos deben limpiarse y prepararse, y luego el rendimiento del modelo debe validarse en varias tareas posteriores. Y finalmente, el modelo debe ser atendido, pero debido a su tamaño, esa es una tarea compleja y que requiere mucha experiencia.
Objetivos y consideraciones para la supercomputadora de IA basada en la nube de IBM
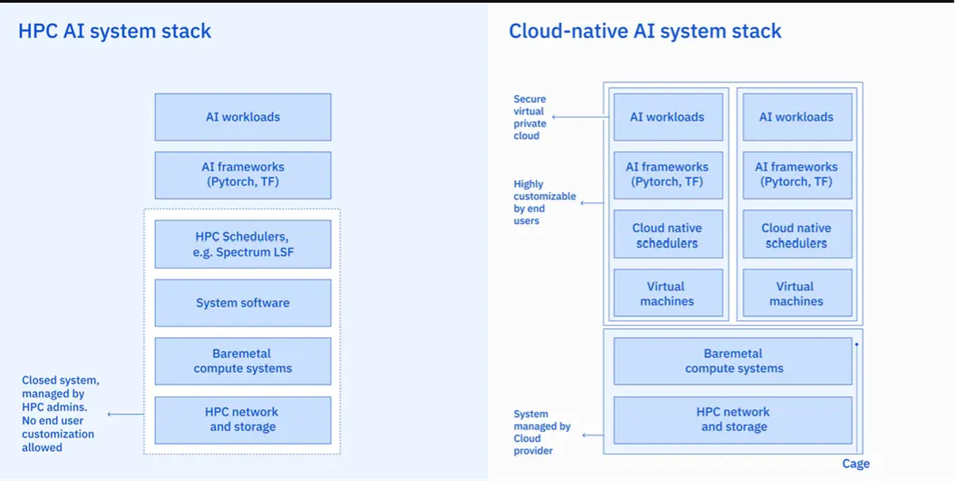
El equipo de investigación de IBM responsable de construir Vela decidió que construir una supercomputadora de IA en la nube proporcionaba la forma más eficiente y efectiva de lograr sus objetivos:
La nube facilita la colaboración entre investigadores y clientes. Proporcionó acceso a varios servicios de nube pública para mejorar la seguridad y la privacidad. El software se podía configurar en cada nodo para satisfacer las necesidades de los equipos de investigación. Con la nube, los investigadores de IA tenían mayor flexibilidad e independencia para acceder a las herramientas y bibliotecas de software más recientes necesarias para los modelos. La alta redundancia de la nube garantizaría que el sistema continuara funcionando en caso de falla de un componente.
Para funcionar correctamente, la infraestructura de IA necesita nodos compuestos por muchas GPU. Los nodos se pueden configurar de una de dos maneras, ya sea como máquinas físicas (comúnmente llamadas "bare metal") que maximizan el rendimiento de la IA o como máquinas virtuales (VM) que brindan a los equipos de soporte la flexibilidad para ajustar la infraestructura y asignar recursos entre cargas de trabajo
El equipo de diseño de la supercomputadora de IA utilizó ingeniería inteligente para combinar las ventajas de las capacidades de los nodos (como GPU, CPU, redes y almacenamiento) con la flexibilidad de las máquinas virtuales (VM). Esto se logró configurando el host para la virtualización, pero asegurándose de que todos los dispositivos y conexiones estuvieran representados con precisión dentro de la máquina virtual. Esto proporcionó a Vela t la capacidad de operar al mismo nivel de rendimiento que una máquina física y al mismo tiempo ofrecer flexibilidad de VM.
Vela: diseñado para un rendimiento casi completo
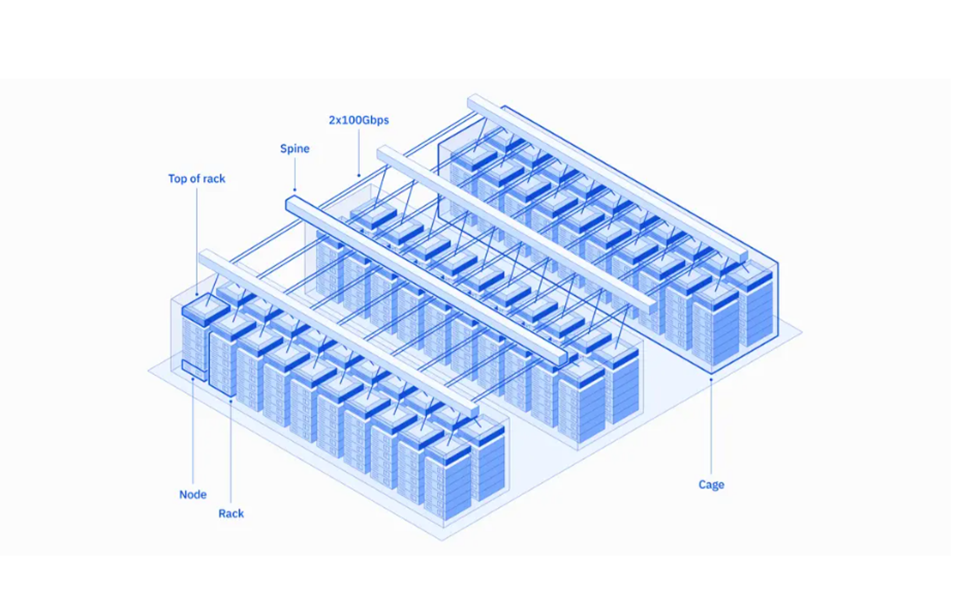
La plataforma de Vela se basa en OpenShift, lo que la hace fácilmente transferible a cualquier nube o entorno híbrido. Es un enorme sistema de varios nodos y varias GPU que utiliza NVlink para la comunicación de alta velocidad entre las GPU. NVSwitch se usa para conectar múltiples NVLinks para comunicaciones de alta velocidad de GPU de todos a todos dentro de un solo nodo. NVSwitch también extiende las comunicaciones a través de los nodos para crear un clúster de GPU de varios nodos, de alto ancho de banda y sin problemas, formando efectivamente una GPU del tamaño de un centro de datos.
El equipo de diseño decidió que Vela necesitaba tecnologías de nube nativas. IBM optó por no construir un sistema InfiniBand, por lo que se eligió Ethernet por su mayor flexibilidad, escalabilidad, facilidad de operación y administración. Igualmente importante, Ethernet hizo que el sistema fuera compatible con la infraestructura de nube de IBM.
Aunque IBM se negó a especificar la cantidad exacta de GPU de Vela, para administrar de manera efectiva los recursos en un sistema de más de mil GPU, IBM desarrolló una tecnología de programación por lotes nativa de la nube que se ejecuta sobre Kubernetes. Esta tecnología está actualmente en uso en el clúster de OpenShift de producción para poner en cola, priorizar y administrar trabajos de manera eficiente.
Terminando
IBM Research ha dedicado una gran cantidad de recursos para crear y entrenar modelos de IA generativos y de gran base en muchos dominios y modalidades. IBM Research se ha asociado con muchas de sus unidades comerciales internas para enfocarse en entrenar modelos de clase mundial de manera más rápida y eficiente para ponerlos en funcionamiento y convertirlos en valor comercial. Debido a que entrenar modelos de IA requiere requisitos de cómputo significativamente diferentes a los de las supercomputadoras clásicas, IBM diseñó y construyó su propia supercomputadora de IA y la implementó en la nube en mayo de 2022.
Los modelos de inteligencia artificial requieren una cantidad excesiva de recursos informáticos y tiempo para construirlos y entrenarlos. La supercomputadora de inteligencia artificial de IBM, Vela, se diseñó en última instancia para construir y entrenar modelos enormes con eficiencia y velocidad.
IBM realizó una cantidad monumental de trabajo de diseño e ingeniería para limitar los gastos generales de rendimiento de Vela a unos pocos puntos porcentuales del metal desnudo. Toda su pila está construida sobre OpenShift, lo que lo hace portátil a cualquier nube, cualquier entorno de nube pública o local, y le da la capacidad de ejecutarse en un entorno de nube híbrida.
Aunque IBM no ha señalado su intención de proporcionar supercomputación de IA basada en la nube como servicio, Vela es una supercomputadora de IA masiva con todas las características y funciones necesarias para tal oferta. La arquitectura es tal que sería sencillo para IBM tomar una porción de la infraestructura de Vela y ofrecerla como un servicio.
Considerándolo todo, no me sorprendería ver una oferta de supercomputadora de IA como servicio en algún momento a principios de 2024. Sería beneficioso para IBM, así como para todo el ecosistema de IA.

