Мозговой чип расширяет возможности искусственного интеллекта и машинного обучения в пространстве и времени с помощью нейронных сетей, вдохновленных биотехнологиями.
Процессоры и сопроцессоры с искусственным интеллектом и машинным обучением (AI/ML) бурно развиваются во встраиваемых периферийных продуктах, поэтому продолжается поиск высокопроизводительных технологий, способных работать с широким спектром моделей AI/ML при очень низком энергопотреблении. Brainchip уже некоторое время продвигает на рынок уникальную, основанную на биологическом вдохновении Akida линейку лицензируемой, настраиваемой интеллектуальной собственности для нейронной обработки. Синтезируемый IP компании предназначен для эффективной реализации рабочих нагрузок AI/ML в качестве встроенного сопроцессора ЦП, который требует минимального вмешательства ЦП. Теперь компания представила архитектуру сопроцессора для нейронной обработки Akida AI/ML второго поколения, которая в нескольких отношениях улучшает IP-архитектуру первого поколения.
Akida IP компании запускает стандартные модели нейронных сетей, построенные со стандартными потоками инструментов AI/ML, но этот IP уникальным образом использует энергоэффективные органические архитектуры мозга, созданные за более чем 100 миллионов лет эволюции, реализуя когнитивную обработку AI/ML с использованием биотехнологии. вдохновленный, но полностью цифровой подход к нейронной обработке. Это радикально отличающийся подход к проектированию по сравнению с большими массивами энергоемких умножителей/аккумуляторов (MAC), встроенных в большинство современных нейронных процессоров AI/ML (NPU). Благодаря уникальному подходу Brainchip к обработке AI/ML, система Akida для нейронной обработки данных компании способна обеспечить обработку в реальном времени с такой же или большей точностью, чем основные решения AI/ML, но со значительно меньшим энергопотреблением.
Архитектура Akida может решить широкий спектр задач AI/ML в ряде встроенных периферийных приложений, включая:
Обнаружение видеообъектов и сети преобразования зрения с использованием изображений с высоким или низким разрешением. Усовершенствованное прогнозирование последовательности.
Эти приложения охватывают множество различных сегментов рынка встроенных периферийных устройств, включая автомобили, умный дом, потребительские товары, здравоохранение, цифровую безопасность и наблюдение, а также промышленную автоматизацию.
Существует несколько факторов, обуславливающих рост периферийной обработки AI/ML по сравнению с облачной обработкой AI/ML. Во-первых, облачные услуги связаны с постоянными операционными расходами, и стоимость этих услуг растет. В то же время облачные решения имеют проблемы с реагированием и задержкой, которые иногда невозможно преодолеть, если обработка AI/ML ограничена облаком. Эта проблема усугубляется быстро растущим использованием облачной обработки для многих рабочих нагрузок, а не только AI/ML, что противопоставляет конкурирующие рабочие нагрузки на серверах центров обработки данных друг другу и создает нагрузку на инфраструктуру, необходимую для передачи данных датчиков на эти серверы. Обработка AI/ML, локализованная на встроенном устройстве, не привязана к облаку, и обработка продолжается независимо от того, подключено ли устройство к сети или нет, что может быть огромным преимуществом в неподключенных или периодически подключаемых приложениях или в зонах с плохим покрытием.
Хотя центры обработки данных и сети являются масштабируемыми, включение обработки AI/ML во встроенные периферийные устройства создает решение, которое автоматически масштабируется при увеличении нагрузки, потому что по мере добавления к периферии большего количества устройств, требующих обработки AI/ML, добавляется больше возможностей обработки AI/ML. также на каждом новом устройстве. Дополнительным преимуществом является то, что хранение данных датчиков, локализованных во встроенном периферийном устройстве, и локальное выполнение обработки AI/ML также позволяют обойти потенциальные проблемы с конфиденциальностью и безопасностью, поскольку частные и защищенные данные недоступны и никогда не передаются по сети.
Основным элементом архитектуры Akida от Brainchip является импульсный NPU, который имитирует работу множества нейронов и синапсов органического мозга. Akida NPU управляется событиями. Он работает только тогда, когда есть данные для обработки, что экономит энергию. Кроме того, каждый NPU Akida имеет собственную локальную память, что избавляет от необходимости обмениваться весами моделей AI/ML во внешней памяти и из нее. Эта функция дополнительно снижает энергопотребление, повышая производительность и устраняя узкие места внешней памяти, вызванные трафиком AI/ML на шинах памяти.
Архитектура Akida объединяет четыре NPU в узел и соединяет несколько узлов с помощью mesh NOC (сеть на кристалле). Эта архитектура может реализовывать стандартные CNN (сверточные нейронные сети), DNN (глубокие нейронные сети), RNN (рекуррентные нейронные сети), сети прогнозирования последовательности, преобразователи зрения и другие типы нейронных сетей в дополнение к собственным сетям Akida NPU, SNN ( спайковые нейронные сети).
Архитектура платформы Akida 2-го поколения добавляет оптимизированное оборудование, называемое узлами Vision Transformer, которые работают с существующими нейроморфными компонентами на основе событий для создания преобразователей видения. Эти сети Vision Transformer достигают отличных результатов в приложениях распознавания изображений, обнаружения объектов и классификации изображений по сравнению с конкурирующими современными сверточными сетями со значительно меньшими вычислительными ресурсами или электрической мощностью. Новая архитектура 2-го поколения имеет аппаратную поддержку соединений с пропуском на большие расстояния и теперь поддерживает 8-, 4-, 2- и 1-битные веса и активации, что позволяет командам разработчиков AI/ML настраивать точность модели, использование памяти и энергопотребление в соответствии с требованиями приложения.
Компания также добавила поддержку того, что компания называет временными нейронными сетями, основанными на событиях (TENN), которые сокращают объем памяти и количество операций, необходимых для рабочих нагрузок, включая прогнозирование последовательности и обнаружение видеообъектов, на порядки при обработке 3D-данных. или данные временного ряда. Что делает TENN особенно интересными, так это возможность получать необработанные данные датчиков без предварительной обработки, что позволяет радикально упростить аудио- или медицинский мониторинг или устройства прогнозирования. Программная среда MetaTF от Brainchip автоматически преобразует другие нейронные сети в SNN. MetaTF работает со стандартными отраслевыми фреймворками, такими как TensorFlow/Keras, и платформами разработки, такими как Edge Impulse.
Существует три различных лицензируемых IP-продукта, основанных на архитектуре платформы Brainchip Akida, как показано на рисунке ниже:
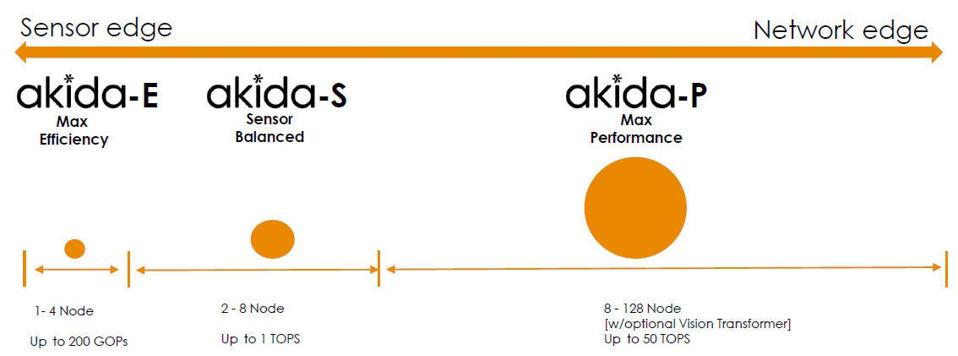
Вариант Max Efficiency (Akida-E) обеспечивает до четырех узлов (или 16 NPU), работает на частоте 200 МГц, обеспечивает производительность, эквивалентную 200 GOPS (гигаопераций в секунду), и потребляет всего милливатт мощности для операция. Компания заявляет, что этот меньший вариант предназначен для запуска более простых сетей AI/ML и предназначен для использования в постоянно работающем оборудовании, где энергопотребление имеет большое значение. Вариант со сбалансированным датчиком (Akida-S) может иметь до восьми узлов (32 NPU), работает на частоте 500 МГц и обеспечивает производительность, эквивалентную 1 TOPS (триллион операций в секунду), которая способна работать рабочие нагрузки по обнаружению и классификации объектов. Вариант Performance (Akida-P) вмещает до 128 узлов (512 NPU), работает на частоте 1,5 ГГц и обеспечивает производительность, эквивалентную 50 TOPS. Самая мощная версия варианта Performance включает дополнительную аппаратную поддержку сетей преобразователей зрения, которые принимают форму дополнительных узлов во внутренней ячеистой сети Akida.
Высокопроизводительный вариант может запускать весь спектр моделей AI/ML в зоопарке моделей Brainchip для выполнения задач, включая классификацию, обнаружение, сегментацию и прогнозирование. Вместе эти варианты Akida позволяют команде разработчиков использовать единую архитектуру AI/ML, которая масштабируется от конфигураций с низким энергопотреблением, которые потребляют всего микроватты энергии, до высокопроизводительных конфигураций, которые обеспечивают десятки TOPS и, согласно BrainChip, могут выполнять видеообъект HD. обнаружение со скоростью 30 кадров в секунду при потреблении менее 75 милливатт, что может привести к созданию очень привлекательных портативных решений для машинного зрения.
Платформа Akida от Brainchip, вдохновленная биологическими технологиями, безусловно, является необычным способом решения задач AI/ML. В то время как большинство других поставщиков NPU выясняют, сколько MAC они могут поместить — и питать — на булавочной головке, Brainchip использует альтернативный подход, который, как доказала мать-природа, работает на протяжении многих десятков миллионов лет.
По мнению Tirias Research, важен не путь к результату, а сам результат. Если событийная платформа Brainchip Akida добьется успеха, это будет не первый случай, когда радикальная новая кремниевая технология захлестнет поле. Рассмотрим, например, DRAM (динамическую память с произвольным доступом), микропроцессоры, микроконтроллеры и FPGA (программируемые пользователем логические матрицы). Когда эти устройства только появились, многие сомневались. Больше никогда. Вполне возможно, что Brainchip разработала еще один прорыв, который может сравниться с предыдущими инновациями. Время покажет.

