Brainchip розширює ШІ, машинне навчання в просторі та часі за допомогою нейронних мереж, натхненних біологією.
Оскільки процесори та співпроцесори зі штучним інтелектом і машинним навчанням (AI/ML) активно розвиваються серед вбудованих периферійних продуктів, продовжується пошук високопродуктивної технології, яка може запускати широкий спектр моделей AI/ML з дуже низьким енергоспоживанням. Brainchip вже деякий час продає лінію унікальних, натхненних біотехнологіями, лінійок Akida з можливістю ліцензування та конфігурації IP нейронної обробки. Синтезований IP компанії розроблений для ефективної реалізації робочих навантажень штучного інтелекту/ML як вбудований у процесор співпроцесор ЦП, який вимагає невеликого втручання ЦП. Тепер компанія представила архітектуру співпроцесора нейронної обробки Akida AI/ML другого покоління, яка декількома способами покращує IP-архітектуру першого покоління.
IP компанії Akida запускає стандартні моделі нейронних мереж, створені за допомогою стандартних потоків інструментів AI/ML, але цей IP унікальним чином використовує енергоефективні органічні архітектури мозку, створені протягом більш ніж 100 мільйонів років еволюції, реалізуючи когнітивну обробку AI/ML за допомогою біо -натхненний, але повністю цифровий підхід до нейронної обробки. Це кардинально інший підхід до проектування порівняно з великими масивами енергоємних помножувачів/акумуляторів (MAC), вбудованих у більшість сучасних нейронних процесорів (NPU) AI/ML. Завдяки унікальному підходу Brainchip до розробки AI/ML-обробки, нейронна обробка IP компанії Akida здатна забезпечувати обробку в реальному часі з такою ж або кращою точністю, ніж стандартні AI/ML-рішення, але зі значно меншими потребами в електроенергії.
Архітектура Akida може вирішувати широкий спектр завдань штучного інтелекту/ML у низці вбудованих периферійних програм, зокрема:
Мережі детектування відеооб’єктів і трансформаторів зору з використанням зображень із високою або низькою роздільною здатністю Розширене передбачення послідовності Виявлення об’єктів, класифікація та локалізація Прогнозування життєво важливих ознак Розширена класифікація звуку, включаючи визначення ключових слів і далі Розпізнавання жестів Аналіз вібрації та виявлення аномалій
Ці додатки охоплюють багато різних сегментів ринку вбудованих периферійних пристроїв, включаючи автомобільну промисловість, розумний дім, споживачів, охорону здоров’я, цифрову безпеку та відеоспостереження, а також промислову автоматизацію.
Існує кілька факторів, які сприяють зростанню рівня обробки периферійних технологій AI/ML порівняно з хмарними обробками AI/ML. По-перше, хмарні послуги становлять постійні операційні витрати, і ці витрати зростають. У той же час хмарні рішення мають проблеми зі швидкістю реагування та затримкою, які іноді неможливо подолати, якщо обробку AI/ML обмежується хмарою. Ця проблема посилюється швидким зростанням використання хмарної обробки для багатьох робочих навантажень, а не лише штучного інтелекту/ML, що протиставляє конкуруючі робочі навантаження на серверах центрів обробки даних і обтяжує інфраструктуру, необхідну для транспортування даних датчиків на ці сервери. Обробка AI/ML, локалізована на вбудованому пристрої, не прив’язана до хмари, і обробка продовжується незалежно від того, під’єднано пристрій до мережі чи ні, що може бути надзвичайною перевагою в непід’єднаних або періодично підключених додатках або в зонах поганого покриття.
Незважаючи на те, що центри обробки даних і мережі можна масштабувати, інтеграція обробки AI/ML у вбудовані периферійні пристрої створює рішення, яке автоматично масштабується зі збільшенням навантаження, оскільки, оскільки більше пристроїв, які потребують обробки AI/ML, додаються до периферії, додається більше можливостей обробки AI/ML. кожним новим пристроєм. Як додаткова перевага, збереження даних датчиків у вбудованому периферійному пристрої та локальна обробка штучного інтелекту/ML також дозволяє уникнути потенційних проблем із конфіденційністю та безпекою, оскільки приватні та захищені дані недоступні та ніколи не проходять через мережу.
Основним елементом архітектури Brainchip Akida є імпульсний NPU, який імітує роботу безлічі нейронів і синапсів органічного мозку. НПУ Акіда керується подіями. Він працює лише тоді, коли є дані для обробки, що економить енергію. Крім того, кожен NPU Akida має власну локальну пам’ять, що усуває необхідність змінювати ваги моделі AI/ML у зовнішній пам’яті та з неї. Ця функція додатково знижує енергоспоживання, підвищуючи продуктивність і усуваючи вузькі місця зовнішньої пам’яті, спричинені трафіком AI/ML на шинах пам’яті.
Архітектура Akida об’єднує чотири NPU в один вузол і з’єднує кілька вузлів за допомогою сітчастого NOC (мережі на кристалі). Ця архітектура може реалізовувати стандартні CNN (згорточні нейронні мережі), DNN (глибокі нейронні мережі), RNN (рекурентні нейронні мережі), мережі прогнозування послідовності, перетворювачі зору та інші типи нейронних мереж на додаток до власних мереж Akida NPU, SNN ( spiking нейронні мережі).
Архітектура платформи Akida 2-го покоління додає оптимізоване обладнання під назвою Vision Transformer nodes, яке працює з існуючими нейроморфними компонентами на основі подій для створення трансформаторів зору. Ці мережі Vision Transformer досягають чудових результатів у програмах розпізнавання зору, виявлення об’єктів і класифікації зображень порівняно з конкуруючими сучасними згортковими мережами зі значно меншими обчислювальними ресурсами чи електроенергією. Нова архітектура 2-го покоління має апаратну підтримку для з’єднань з пропусканням на великій відстані та тепер підтримує 8-, 4-, 2- та 1-бітні ваги та активації, що дозволяє командам розробників AI/ML налаштовувати точність моделі, використання пам’яті та енергоспоживання відповідно до вимог програми.
Компанія також додала підтримку того, що компанія називає часовими нейронними мережами на основі подій (TENN), які зменшують обсяг пам’яті та кількість операцій, необхідних для робочих навантажень, включаючи прогнозування послідовності та виявлення відеооб’єктів, на порядки при обробці 3D-даних. або дані часових рядів. Те, що робить TENN особливо цікавим, так це можливість отримувати необроблені дані датчиків без попередньої обробки, що дозволяє радикально спростити аудіосистеми або пристрої для моніторингу охорони здоров’я чи прогнозування. Програмна структура MetaTF від Brainchip автоматично перетворює інші нейронні мережі на SNN. MetaTF працює зі стандартними фреймворками, такими як TensorFlow/Keras, і платформами розробки, такими як Edge Impulse.
На основі архітектури платформи Akida компанії Brainchip є три окремі ліцензовані IP-продукти, як показано на малюнку нижче:
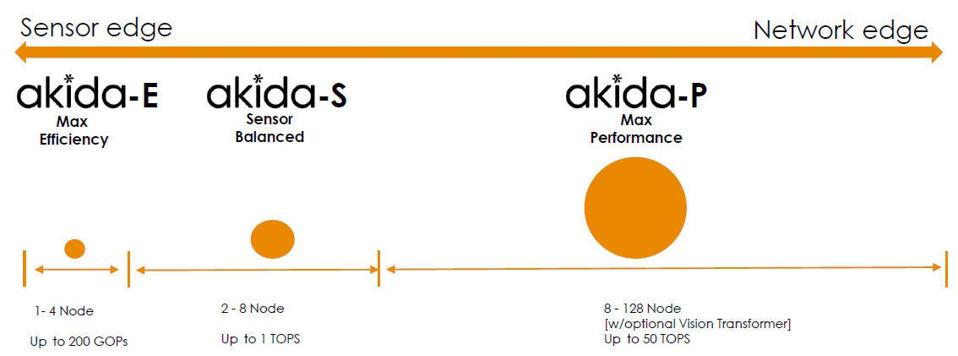
Варіант Max Efficiency (Akida-E) забезпечує до чотирьох вузлів (або 16 NPU), працює зі швидкістю 200 МГц, забезпечує продуктивність, еквівалентну 200 GOPS (гігаоперацій за секунду), і потребує лише міліват потужності для операція. У компанії кажуть, що цей менший варіант розроблений для роботи з простішими мережами AI/ML і призначений для використання в безперервно працюючому обладнанні, де енергоспоживання є високим. Варіант Sensor Balanced (Akida-S) може бути налаштований із вісьмома вузлами (32 NPU), працює на частоті 500 МГц і забезпечує продуктивність, еквівалентну 1 TOPS (трильйону операцій на секунду), яка здатна працювати виявлення та класифікація об’єктів. Варіант продуктивності (Akida-P) містить до 128 вузлів (512 NPU), працює на частоті 1,5 ГГц і забезпечує еквівалент 50 TOPS. Найпотужніша версія варіанту Performance включає додаткову апаратну підтримку для мереж трансформаторів зору, які приймають форму додаткових вузлів у внутрішній сітчастій мережі Akida.
Варіант високого класу може працювати з повною гамою моделей AI/ML у модельному зоопарку Brainchip для виконання завдань, включаючи класифікацію, виявлення, сегментацію та прогнозування. Разом ці варіанти Akida дозволяють команді розробників використовувати одну архітектуру AI/ML, яка масштабується від конфігурацій з низьким споживанням електроенергії, які споживають лише мікроват, до високопродуктивних конфігурацій, які забезпечують десятки TOPS, і, за даними BrainChip, можуть створювати об’єкти HD-відео. виявлення зі швидкістю 30 кадрів на секунду, споживаючи менше 75 міліват, що може призвести до дуже переконливих рішень для портативного зору.
Платформа Akida від Brainchip, натхненна біологією, безумовно, є незвичайним способом вирішення програм AI/ML. У той час як більшість інших постачальників NPU з’ясовують, скільки MAC вони можуть вмістити – і потужність – на голівці шпильки, Brainchip використовує альтернативний підхід, який, як доведено матінкою-природою, працює протягом багатьох десятків мільйонів років.
На думку Tirias Research, важливий не шлях до результату, а результат. Якщо подійна платформа Brainchip Akida досягне успіху, це буде не перший випадок, коли радикально нова кремнієва технологія охопить поле. Розглянемо, наприклад, DRAM (динамічну пам’ять з довільним доступом), мікропроцесори, мікроконтролери та FPGA (програмовані вентильні матриці). Коли ці пристрої вперше з’явилися, багато хто висловлював сумніви. Більше не. Цілком можливо, що Brainchip розробив ще один прорив, який міг би зрівнятися з попередніми інноваціями. Час покаже.

