Нужен чат-бот для вашего бизнеса? Попробуйте NVIDIA NeMo.

Nemo может помочь организациям адаптировать модели ИИ, чтобы сосредоточиться на меньшей области; и, возможно, избежать дорогостоящих ошибок!
Лесли Стал: «О, мой бог. Это не правильно!" Репортер-ветеран был ошеломлен тем, что Microsoft Bing может так просто сделать что-то неправильное.

Г-жа Шталь брала интервью у руководителей Microsoft о ее недавнем Bing с GPT на канале CBS 60 Minutes. В качестве демонстрации они спросили могучего Бинга: «Кто такой Лесли Шталь?». А ИИ уверенно ответила, что она журналистка, проработавшая на NBC 20 лет. Хотя разница между CBS и NBC может быть незначительной для ИИ, публичная ошибка была своевременна, чтобы показать, насколько болезненно неправильными могут быть модели больших языков.
Как мы увидим, для эффективной разработки и развертывания больших моделей для специфических для компании вариантов использования небольшая концентрация и настройка могут иметь большое значение.
Что такое NeMo, опять же?
NVIDIA в течение нескольких лет разрабатывает собственную структуру больших моделей под названием NeMo и выпустила код и сервис для облегчения и упрощения разработки и развертывания больших языковых моделей (LLM). Прежде чем мы поговорим о том, что такое NeMo*, давайте рассмотрим вопрос «*почему*. Очевидно, что из-за всей шумихи вокруг ChatGPT в последнее время NVIDIA хочет помочь организациям разрабатывать модели, которые можно настраивать и обучать для решения конкретных бизнес-задач. Адаптация LLM может повысить его эффективность и уменьшить галлюцинации. Вместо того, чтобы просто сказать: «LLM — это круто! Посмотрите, что может сделать OpenAI. Удачи вам в работе над вашей собственной моделью!» NVIDIA показывает пример своим клиентам, показывая им путь вперед в LLM и изобретая способ, с помощью которого эти клиенты могут опираться на передовой опыт отрасли.
Используя NeMo, разработчики могут создавать новые модели и обучать их, используя вычисления смешанной точности на тензорных ядрах в графических процессорах NVIDIA с помощью простых в использовании интерфейсов прикладного программирования (API). Но, возможно, что более важно, NeMo можно использовать для настройки этих моделей и проверки подсказок для соответствующих ответов.
NeMo Megatron — это комплексная контейнерная платформа, которая обеспечивает высокую эффективность обучения на тысячах графических процессоров и позволяет предприятиям создавать и развертывать крупномасштабные модели. Он предоставляет возможности для сбора обучающих данных, обучения крупномасштабных моделей с триллионами параметров, настройки с использованием методов быстрого обучения и развертывания с помощью NVIDIA Triton Inference Server для запуска крупномасштабных моделей на нескольких графических процессорах и узлах.
NeMo LLM Service включает в себя модель Megatron 530B для быстрого экспериментирования с одной из самых мощных в мире языковых моделей и помогает клиентам быстро освоиться с предварительно обученной моделью в качестве отправной точки.
Итак, кто такая Лесли Стал?
Итак, вернемся к Лесли. Как уберечь LLM от глупых ошибок? Что ж, вы можете сфокусировать ИИ на том, какие проблемы вы хотите решить. NVIDIA применила подход «Быстрое обучение» для решения этой проблемы, предоставляя ИИ некоторый контекст, в котором он может ответить на запрос. Обучение на основе подсказок, или P-Tuning, — это стратегия, которую инженеры по машинному обучению могут использовать для обучения и фокусировки LLM, чтобы одну и ту же модель можно было использовать для разных задач без повторного обучения. Теперь правильное получение подсказок может создать новую проблему, и так родилась «инженерная подсказка». Но, по крайней мере, вы можете использовать эти созданные подсказки, чтобы сфокусировать LLM и, возможно, избежать новых бедствий Лесли Штала.
Методы быстрого обучения
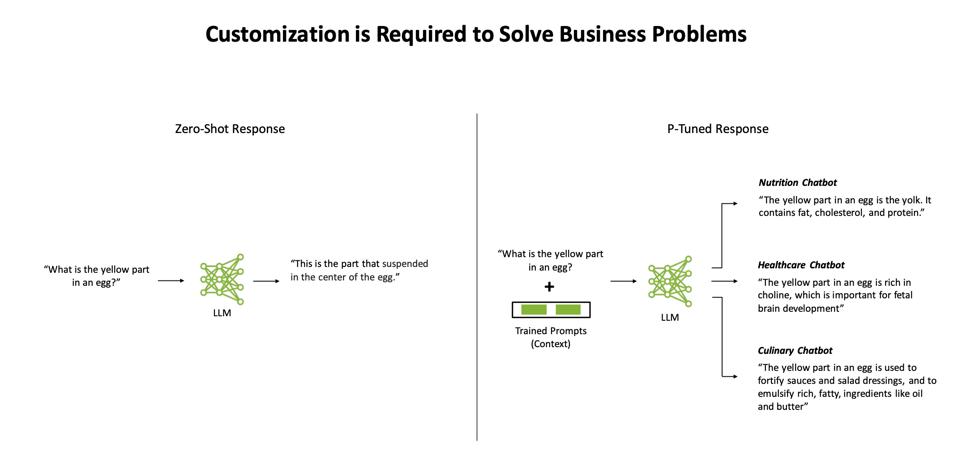
Примером клиента NeMo является AI Sweden, консорциум, возглавляющий переход страны в эпоху машинного обучения. Небольшая исследовательская группа из 6 человек в Швеции создала LLM с использованием NeMo, чтобы помочь гражданам получить ответы, которые им нужны, на их родном языке. Параметр 3.6B «GPT-SW3» был обучен с использованием всего 16 узлов DGX, и инженеры NVIDIA решили использовать P-настройку, чтобы удвоить точность небольшой модели. Команда надеется добавить другие скандинавские языки, такие как шведский, датский, норвежский и, возможно, исландский, используя остальные 60 узлов своего суперкомпьютера, размещенного в Университете Линчёпинга.
Более того, для GPT-SW3 требуется в десять раз меньше данных, что сокращает потребность в десятках тысяч записей с ручной маркировкой. Это открывает перед пользователями возможность тонкой настройки модели с помощью имеющихся у них относительно небольших отраслевых наборов данных.

Выводы
NeMo — еще один пример программного обеспечения NVIDIA, которое превращает кремний в решения. Это может помочь клиентам использовать возможности LLM при значительном снижении затрат и рисков.
Меня часто спрашивают о долговечности программного рва NVIDIA CUDA, который защищает компанию от вторжений стартапов. Ответ заключается в том, что вопрос неверен. Это не просто CUDA, как мы часто говорили раньше. Это полный стек NVIDIA, состоящий примерно из 14 конкретных сред искусственного интеллекта и всего базового программного обеспечения, которое конкуренты должны будут воспроизвести. Я не думаю, что они могут или будут, по крайней мере, не в обозримом будущем. Большинство из них все еще просто пытаются приблизить свое оборудование к графическим процессорам NVIDIA.
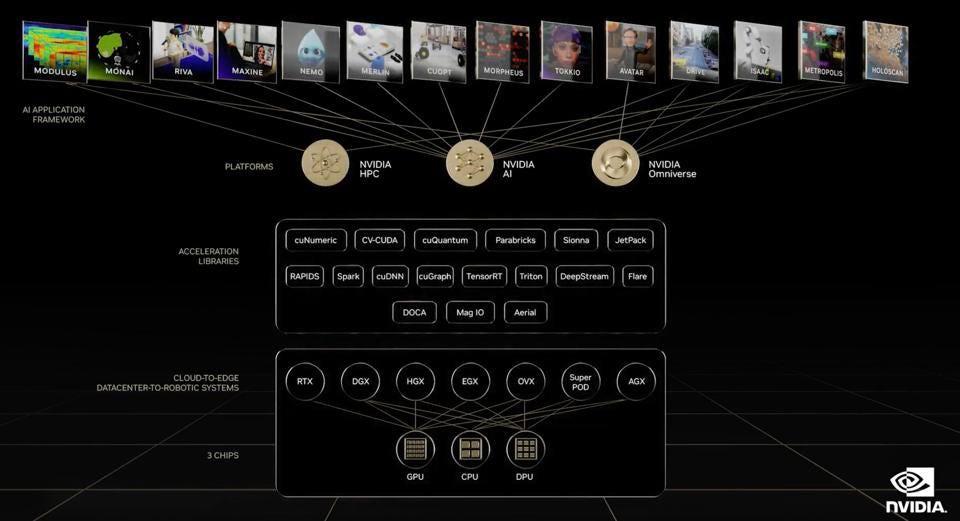
NeMo и модель Megatron — лишь одни из 14. Хотите поговорить об автономном вождении? Здравоохранение? Моделирование высокопроизводительных вычислений? Мета (омни-) стих? Да, они все это получили. И о многих новых инициативах будет объявлено на основном докладе Дженсена Хуанга GTC в следующий вторник.
Я не пропущу это.

