¿Necesita un Chat-Bot para su negocio? Prueba NVIDIA NeMo.

Nemo puede ayudar a las organizaciones a adaptar los modelos de IA para centrarse en un dominio más pequeño; ¡y tal vez evitar errores costosos!
Lesley Stahl: “Oh, Dios mío. ¡Está incorrecto!" El reportero veterano estaba horrorizado de que Microsoft Bing pudiera hacer algo tan fácil y tan mal.

La Sra. Stahl estaba entrevistando a ejecutivos de Microsoft sobre su reciente Bing equipado con GPT en CBS 60 Minutes. Como demostración, le preguntaron al poderoso Bing: "¿Quién es Lesley Stahl?". Y la IA respondió con confianza que ella es una periodista que ha pasado 20 años trabajando en NBC. Si bien la diferencia entre CBS y NBC puede no ser significativa para la IA, el error público fue oportuno para mostrar cuán dolorosamente erróneos pueden ser los modelos de lenguaje grande.
Como veremos, con el fin de desarrollar e implementar de manera efectiva modelos grandes para casos de uso específicos de la empresa, un poco de enfoque y personalización pueden ser de gran ayuda.
¿Qué es NeMo, otra vez?
NVIDIA ha estado desarrollando su propio marco de modelo grande, llamado NeMo durante varios años y ha lanzado el código y el servicio para facilitar y simplificar el desarrollo y la implementación del modelo de lenguaje grande (LLM). Antes de hablar sobre lo que *es* NeMo, exploremos el “*por qué*. Obviamente, con todo el alboroto sobre ChatGPT en los últimos tiempos, NVIDIA quiere ayudar a las organizaciones a desarrollar modelos que puedan ajustarse y capacitarse para resolver su problema comercial específico. Adaptar el LLM puede mejorar su eficacia y reducir las alucinaciones. En lugar de simplemente decir: “¡Los LLM son geniales! Mira lo que puede hacer OpenAI. ¡Buena suerte para que su propio modelo funcione!”, NVIDIA lidera con el ejemplo, mostrando a los clientes el camino a seguir en el LLM e inventando una manera para que esos clientes desarrollen el cuerpo de trabajo de la industria.
Con NeMo, los desarrolladores pueden crear nuevos modelos y entrenarlos usando computación de precisión mixta en Tensor Cores en GPU NVIDIA a través de interfaces de programación de aplicaciones (API) fáciles de usar. Pero quizás lo más importante es que NeMo se puede usar para personalizar estos modelos y probar las indicaciones para obtener las respuestas adecuadas.
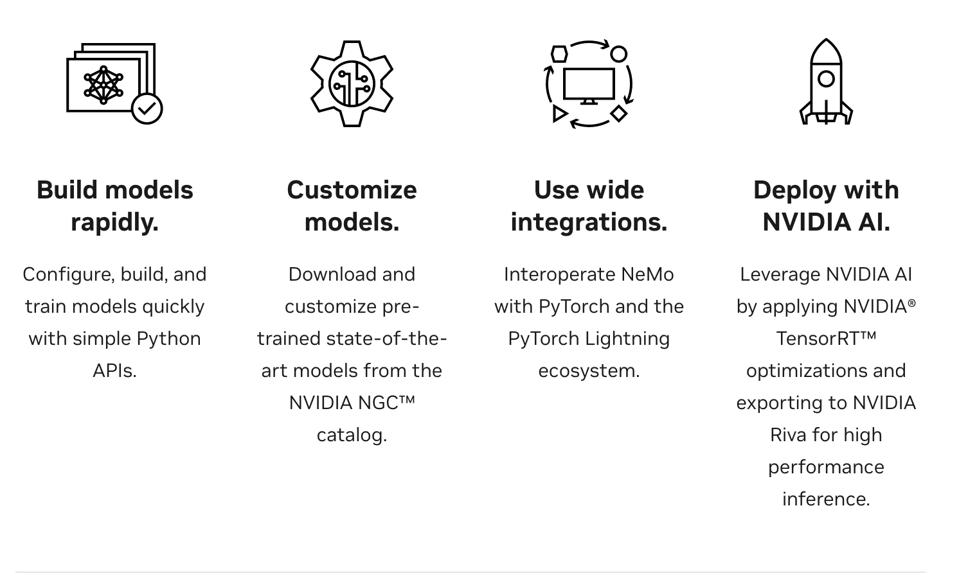
NeMo Megatron es un marco de trabajo en contenedores de extremo a extremo que ofrece una alta eficiencia de capacitación en miles de GPU y hace que sea práctico para las empresas construir e implementar modelos a gran escala. Brinda capacidades para seleccionar datos de entrenamiento, entrenar modelos a gran escala hasta billones de parámetros, personalizar usando técnicas de aprendizaje rápido e implementar con NVIDIA Triton Inference Server para ejecutar modelos a gran escala en múltiples GPU y nodos.
NeMo LLM Service incluye el modelo Megatron 530B para una experimentación rápida con uno de los modelos de lenguaje más poderosos del mundo y ayuda a los clientes a ponerse al día rápidamente con un modelo previamente entrenado como punto de partida.
Ahora, ¿quién es Lesley Stahl?
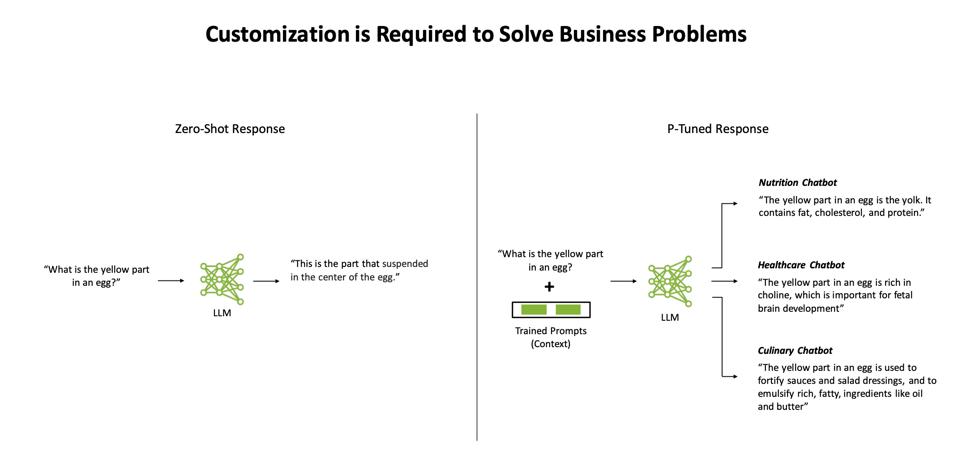
Entonces, volvamos a Leslie. ¿Cómo se evita que un LLM cometa errores estúpidos? Bueno, puedes enfocar la IA en los problemas que quieres que resuelva. NVIDIA ha adoptado el enfoque de "aprendizaje rápido" para resolver este problema, lo que le da a la IA un contexto dentro del cual puede responder una consulta. El aprendizaje basado en indicaciones, o P-Tuning, es una estrategia que los ingenieros de aprendizaje automático pueden usar para capacitar y enfocar los LLM para que el mismo modelo se pueda usar para diferentes tareas sin volver a capacitarse. Ahora, obtener los avisos correctos puede crear un nuevo desafío, y nace la "ingeniería de avisos". Pero al menos puede usar estas indicaciones diseñadas para enfocar el LLM y posiblemente evitar más desastres de Lesley Stahl.
Técnicas de aprendizaje rápido
Un ejemplo de cliente de NeMo es AI Suecia, un consorcio que lidera el viaje del país hacia la era del aprendizaje automático. El pequeño grupo de investigación de 6 personas en Suecia ha creado un LLM utilizando NeMo para ayudar a los ciudadanos a obtener las respuestas que necesitan en su idioma local. El parámetro 3.6B "GPT-SW3" se entrenó con solo 16 nodos DGX, y los ingenieros de NVIDIA colaboraron para usar el ajuste P para duplicar la precisión del modelo pequeño. El equipo espera agregar otros idiomas nórdicos como sueco, danés, noruego y posiblemente islandés, usando el resto de los 60 nodos en su supercomputadora ubicada en la Universidad de Linköping.
Además, GPT-SW3 requiere una décima parte de los datos, lo que reduce drásticamente la necesidad de decenas de miles de registros etiquetados a mano. Eso abre la puerta para que los usuarios ajusten un modelo con los conjuntos de datos relativamente pequeños y específicos de la industria que tienen a mano.

Conclusiones
NeMo es otro ejemplo más del software de NVIDIA que convierte el silicio en soluciones. Puede ayudar a los clientes a adoptar el poder de los LLM, a un costo y riesgo significativamente reducidos.
A menudo me han preguntado sobre la durabilidad del foso de software CUDA de NVIDIA que protege a la empresa de las incursiones de las nuevas empresas. La respuesta es que la pregunta es incorrecta. No es solo CUDA, como hemos dicho muchas veces antes. Es la pila completa de NVIDIA de unos 14 marcos de trabajo de IA específicos y todo el software subyacente que los competidores tendrán que replicar. No creo que puedan o lo hagan, al menos no en un futuro previsible. La mayoría todavía está tratando de acercar su hardware a las GPU de NVIDIA.
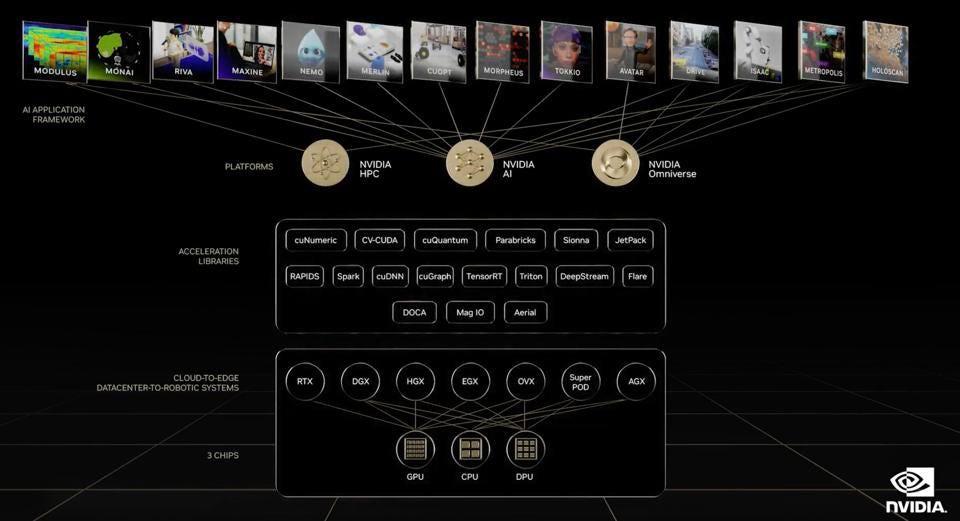
NeMo y el modelo Megatron son solo uno de los 14. ¿Quieres hablar sobre la conducción autónoma? ¿Cuidado de la salud? ¿simulaciones HPC? ¿El Meta (Omni-) verso? Sí, tienen todo eso. Y se anunciarán muchas iniciativas nuevas en el discurso de apertura de GTC de Jensen Huang el próximo martes.
no me lo perderé

