Потрібен чат-бот для вашого бізнесу? Спробуйте NVIDIA NeMo.

Nemo може допомогти організаціям адаптувати моделі штучного інтелекту, щоб зосередитися на меншому домені; і, можливо, уникнути дорогих помилок!
Леслі Шталь: «Боже мій. Це неправильно!" Ветеран-репортер був приголомшений тим, що Microsoft Bing міг щось так легко зробити так неправильно.

Пані Шталь брала інтерв’ю у керівників корпорації Майкрософт про її нещодавно оснащений GPT Bing на CBS 60 Minutes. У якості демонстрації вони запитали могутнього Бінга: «Хто така Леслі Шталь?». А ШІ впевнено відповіла, що вона журналістка, яка 20 років пропрацювала на NBC. Хоча різниця між CBS і NBC може бути несуттєвою для штучного інтелекту, публічна помилка була вчасно підготовлена, щоб показати, наскільки невірними можуть бути великі мовні моделі.
Як ми побачимо, щоб ефективно розробляти та розгортати великі моделі для конкретних випадків використання компанії, невелика концентрація та налаштування можуть мати велике значення.
Знову ж таки, що таке NeMo?
NVIDIA протягом кількох років розробляла власну структуру великої моделі під назвою NeMo та випустила код і сервіс, щоб полегшити та спростити розробку та розгортання моделі великої мови (LLM). Перш ніж ми поговоримо про те, що таке *NeMo*, давайте дослідимо «*чому*. Очевидно, що враховуючи весь галас про ChatGPT останнім часом, NVIDIA хоче допомогти організаціям розробити моделі, які можна налаштувати та навчити для вирішення їхніх конкретних бізнес-проблем. Пристосування LLM може підвищити його ефективність і зменшити галюцинації. Замість того, щоб просто сказати: «LLM — це круто! Подивіться, що може OpenAI. Успіхів вам у тому, щоб ваша власна модель запрацювала!», NVIDIA є прикладом, показуючи клієнтам шлях магістра права та винаходячи спосіб для цих клієнтів надбудовувати галузеві роботи.
Використовуючи NeMo, розробники можуть створювати нові моделі та навчати їх, використовуючи обчислення змішаної точності на тензорних ядрах у графічних процесорах NVIDIA через прості у використанні інтерфейси прикладного програмування (API). Але, мабуть, ще важливіше, що NeMo можна використовувати для налаштування цих моделей і перевірки підказок відповідних відповідей.
NeMo Megatron — це наскрізна контейнерна структура, яка забезпечує високу ефективність навчання на тисячах графічних процесорів і робить підприємства практичними для створення та розгортання великомасштабних моделей. Він надає можливості для контролю навчальних даних, навчання великомасштабних моделей до трильйонів параметрів, налаштування за допомогою методів швидкого навчання та розгортання за допомогою NVIDIA Triton Inference Server для запуску великомасштабних моделей на кількох графічних процесорах і вузлах.
Служба NeMo LLM включає модель Megatron 530B для швидкого експериментування з однією з найпотужніших у світі мовних моделей і допомагає клієнтам швидко освоїтися, використовуючи попередньо навчену модель як відправну точку.
Хто така Леслі Шталь?
Отже, повернемося до Леслі. Як запобігти LLM робити дурні помилки? Що ж, ви можете зосередити ШІ на тому, які проблеми ви хочете вирішити. Щоб вирішити цю проблему, NVIDIA застосувала підхід «Швидке навчання», надаючи штучному інтелекту певний контекст, у якому він може відповісти на запит. Швидке навчання, або P-Tuning, — це стратегія, яку інженери машинного навчання можуть використовувати для навчання та зосередження LLM, щоб ту саму модель можна було використовувати для різних завдань без повторного навчання. Тепер правильне отримання підказок може створити новий виклик, і народилася «оперативна інженерія». Але принаймні ви можете використовувати ці підказки, щоб зосередитися на LLM і, можливо, уникнути нових катастроф Леслі Шталь.
Методи швидкого навчання
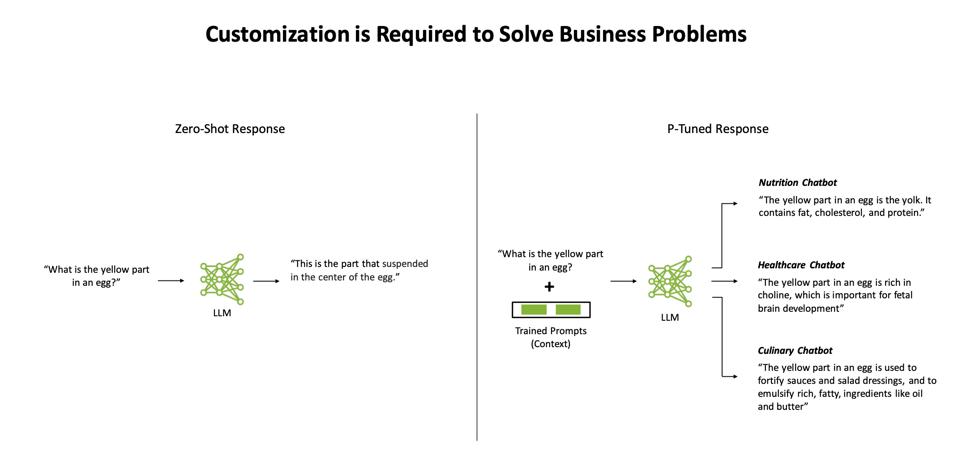
Прикладом клієнта NeMo є AI Sweden, консорціум, який веде шлях країни в еру машинного навчання. Невелика дослідницька група з 6 осіб у Швеції побудувала LLM, використовуючи NeMo, щоб допомогти громадянам отримувати відповіді, які їм потрібні, рідною мовою. Параметр 3.6B «GPT-SW3» був навчений з використанням лише 16 вузлів DGX, і інженери NVIDIA взяли участь у використанні P-налаштування, щоб подвоїти точність маленької моделі. Команда сподівається додати інші скандинавські мови – шведську, датську, норвезьку та, можливо, ісландську, використовуючи решту 60 вузлів у своєму суперкомп’ютері, розміщеному в університеті Лінчепінг.
Більше того, GPT-SW3 вимагає одну десяту даних, скорочуючи потребу в десятках тисяч записів із мітками вручну. Це відкриває можливість користувачам точно налаштувати модель за допомогою відносно невеликих галузевих наборів даних, які вони мають під рукою.

Висновки
NeMo — це ще один приклад програмного забезпечення NVIDIA, яке перетворює кремній на рішення. Це може допомогти клієнтам скористатися потужністю LLM зі значно меншими витратами та ризиками.
Мене часто запитували про довговічність програмного забезпечення NVIDIA CUDA, яке захищає компанію від вторгнень стартапів. Відповідь полягає в тому, що питання неправильне. Це не просто CUDA, як ми часто говорили раніше. Це весь стек NVIDIA з приблизно 14 конкретних фреймворків штучного інтелекту та всього базового програмного забезпечення, яке конкуренти повинні будуть відтворити. Я не думаю, що вони зможуть або не будуть, принаймні в осяжному майбутньому. Більшість досі просто намагаються наблизити своє обладнання до графічних процесорів NVIDIA.
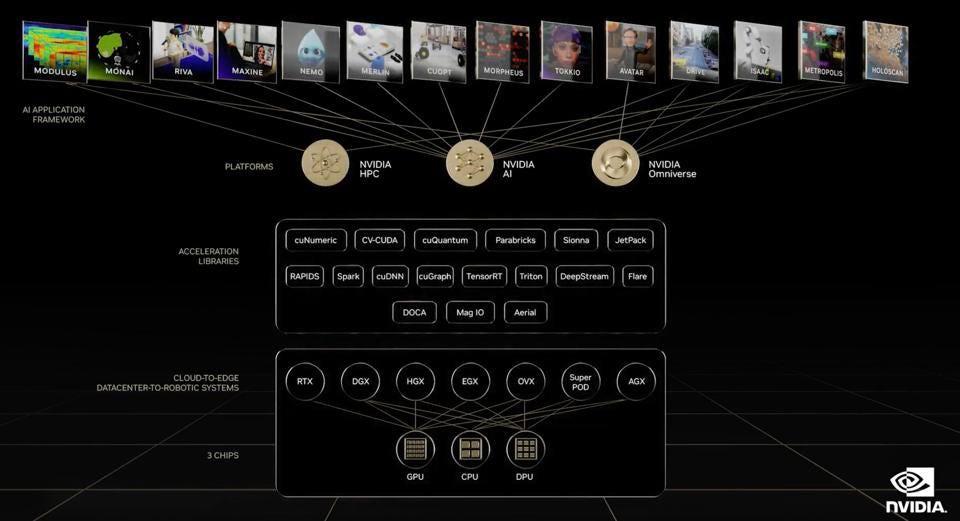
NeMo та модель Megatron лише одні з 14. Хочете поговорити про автономне водіння? Охорона здоров'я? HPC моделювання? Мета (Омні-) вірш? Так, вони все це отримали. І багато нових ініціатив буде оголошено під час доповіді Дженсена Хуанга GTC наступного вівторка.
Я не пропущу це.

